Four Fundamentals When Parallel Processing Data
Parallel processing is a large topic, with the capability to add a lot of complexity to your code. But, if the data and computing environment are up to it, you can produce some impressive performance increases. Here are four things you should know, before getting started.
Serial vs Parallel
Serial processing tends to be how most of us will begin writing code to process data. Whether it loops over the items in a collection, or processes data sets in turn, this kind of processing does operations on one thing at a time.
Parallel processing aims to improve performance of code by doing many things at a time. For instance, processing all the elements in an array simultaneously, or doing analysis on a group of data sets at the same time. There are are numerous ways that different technologies can achieve this, some will do it without you realising, others will require the programmer to exercise more explicit control.
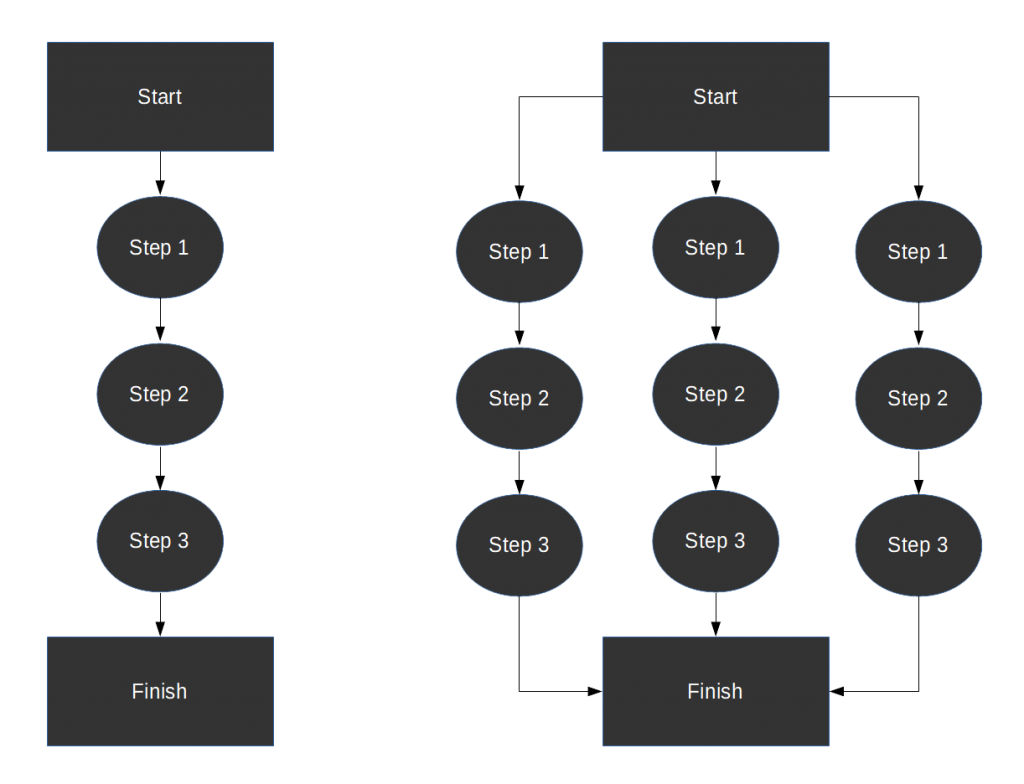 Serial on the left; one item at a time goes through the processing steps. Parallel on the right; three items can go through the processing steps simultaneously.
Serial on the left; one item at a time goes through the processing steps. Parallel on the right; three items can go through the processing steps simultaneously.
Computer hardware
A computer can be thought of in three components, with an optional fourth connecting multiple computers. The three components are physical storage (disk, hard drive), memory (RAM) and processors (cores, CPUs). When processing data from a file, it has to get from the physical storage, in to the memory of the computer and then be operated on by the processor. The optional fourth component is the network between machines if your data sits on a file server.
One of the above will be the limiting factor in your code. Technologies that use serial processing by default, will generally only use one CPU of a computer. Running code on a server with fast storage, lots of memory and many cores, can be limited to the speed of a single CPU. In this situation, parallel processing can improve performance by spreading the processing over many more CPUs.
What’s important to note here, is that parallel processing is not always going to be faster. If your data is read from/written to a rickety old piece of storage at every step, then parallel processing will just put more strain on that component. Also, when ramping up how many CPUs you use, do so slowly. Overloading the processors on your server won’t make you popular, and will make your processing grind to halt!
Threads or Processes
A computer application’s executable (run-able) code is almost always stored on disk. When a user or another program wants to make use of the application, the operating system runs the code in a process. A running process (normally) has exclusive access to a region of memory, gets turns using a processor and can request/receive data.
A thread can be spawned by a process, and behaves in a similar way; you could think of them as sub-processes. Whenever one application is appearing to do more than one thing at once, it is usually because threads are being used. A word processing engine could be downloading updates, whilst still being responsive to user input; these tasks can be achieved through separate threads.
Why does this matter when parallel processing data? You’ll need to understand the technology your using and whether it’s possible to utilise extra threads (C#, Java), or whether you might be better off using an entirely new executable (SAS); there are also cases where you could use either (SAS DS2, for instance). Using a new executable might mean you have to get familiar with start-up options and configuration, things that an admin would normally set for you.
Data Considerations
Assuming you’ve got a nice big server (or lots of smaller ones) to process your data with, you should think carefully about the data itself before making the decision to go parallel.
Ideally the data will be easily split in to separate pieces that don’t influence each other. If your hoping to convert existing serial code to parallel processing, there may be significant overhead in separating out your data structure.
Applications I’ve used parallel processing for include: converting separate XML files to data sets; pushing multiple groupings of data through the same code; running highly iterative models. All of these uses had clear seams where data could be separated off, into groups that didn’t need to interact with each other.
Finally
If this sort of thing floats your boat, and it does mine, be sure to make clear how much processing time you save by parallel processing. I like to have code that can easily run in serial as well as parallel, so that a direct comparison can be made.
Regardless of technical ability, there aren’t many management teams or decision makers who don’t want answers faster. In my experience parallel processing has increased processing speed by 10-50 times; meaning a model or processing can be run many times a day, rather than just once.